
第三回: 正規表現と有限オートマトン
2005年 5月 6日
© 2005 Martin J. Dürst 青山学院大学
| 文法 | Type | 言語 | オートマトン |
| 句構造文法 | 0 | 句構造言語 | チューリング機械 |
| 文脈依存文法 | 1 | 文脈依存言語 | 線形拘束オートマトン |
| 文脈自由文法 | 2 | 文脈自由言語 | プッシュダウンオートマトン |
| 正規文法 | 3 | 正規言語 | 有限オートマトン |
正規言語は字句解析の時に使う。
これらは全て同じ力を持って、正規言語を定義・受理する
(automaton はギリシア語で、複数は automata)
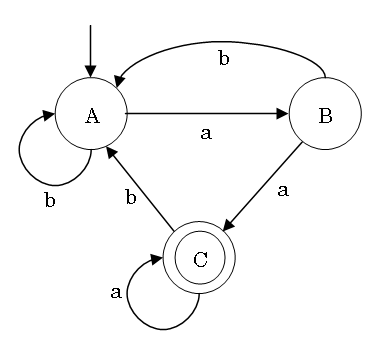
| a | b | |
|---|---|---|
| A | B | A |
| B | C | A |
| C | C | A |
| 決定性 | 非決定性 | |
| 同時に | 一つの状態 | 複数の状態 |
| 受理条件 | 状態が受理状態 | 状態の一つ以上が受理状態 |
| ε 遷移 | 不可 | 可能 |
| 動作関数 | δ: Q × Σ → Q | δ: Q × (Σ ∪ {ε}) → 2Q |
アルゴリズムの原理:
全ての DFA は NFA でもある。全ての NFA は同等の DFA に変換できる。
よって、DFA と NFA の受理能力が等しい。
実装は DFA の方が簡単が、テーブルは大きくなる恐れがある。
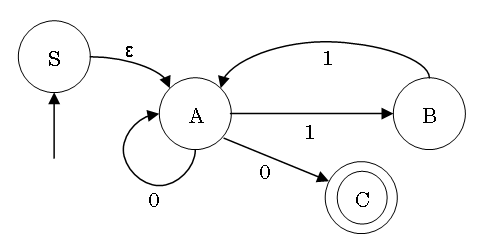
| ε | 0 | 1 | |
| S | {A} | {} | {} |
| A | {} | {A,C} | {B} |
| B | {} | {} | {A} |
| C | {} | {} | {} |
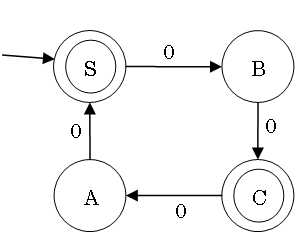
ある DFA から同等の最小の DFA を次の通りに作れる:
最小化によって効率よい実装ができるし、二つの有限オートマトンが同等であるかどうかも簡単に調べられる。
| 規則の形 | 名称 |
| A → aB | 左線形規則 |
| A → Ba | 右線形規則 |
| A → a | 定数規則 |
左線形文法: 左線形規則と定数規則しか含まない文法
右線形文法: 右線形規則と定数規則しか含まない文法
左・右線形文法はともに線形文法と言い、正規文法とも言う
左線形文法と NFA の対応 (ε が考慮外):
右線形文法も同様 (語を右から読み込むと考えられる)
A → aB | bA
B → bA | a | aC
C → bA | a | aC
| 正規表現 | 条件 | 言語 | 備考 |
|---|---|---|---|
| ε, a | a ∈ Σ | {ε} 又は {a} | |
| r|s | r, s が正規表現 | L(r|s) = L(r) ∪ L(s) | 集合和 |
| rs | r, s が正規表現 | L(rs) = L(r)L(s) | 連結 |
| r* | r が正規表現 | L(r*) = (L(r))* | 閉含 |
| (r) | r が正規表現 | L((r)) = L(r) |
L(r) は r によって表されている言語。優先度は下の方が強い。
正規表現を定義する言語は文法で書けるが、正規表現は文法と違って規則は一つしか使わない。
正規表現の便利な追加機能
正規表現の使い方による変更
正規表現に対応する NFA は正規表現の部分表現から再帰的に作られる。
ε と a に対応する NFA は初期状態一つと受理状態一つとそれを結ぶ ε 又は a と書かれた矢印。
r|s の NFA は r の NFA と s の NFA から次のようにつくる:
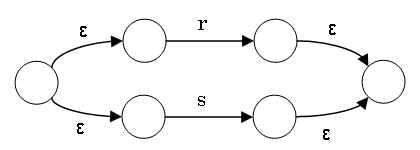
rs の NFA は r の受理状態と s の初期状態を ε で結んで、r の初期状態は rs の初期状態、s の受理状態は rsの受理状態。
r* の NFA は次のようにつくる:
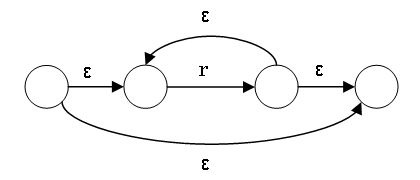
NFA や DFA から正規表現を作るのも可能だが、複雑。
(Element) Content Model ((要素) 内容モデル) の定義: http://www.w3.org/TR/REC-xml/#sec-element-content
(Element) Content Model ((要素) 内容モデル) の例:
<!ELEMENT div1 (head, (p | list | note)*, div2*)>
この内容モデルに相当する XML の部分の一例:
<div1><head>This is the Title</head> <p>Short introduction...</p> <div2>...</div2> <div2>...</div2> </div1>
要素内容モデルは要素を字にした正規表現。
a(b|c)*a