言語理論とコンパイラ
第四回:
正規表現と字句解析
2011 年 5 月 11 日
http://www.sw.it.aoyama.ac.jp/2012/Compiler/lecture4.html
Martin J. Dürst

© 2005-12 Martin
J. Dürst 青山学院大学
今日の内容
- 前回の宿題
- 正規表現
- 正規表現の形式定義
- 正規表現から NFA へ
- 有限オートマトンから正規表現へ
- 実用化された正規表現
前回の宿題
[都合により削除]
今週の展望
- 有限オートマトン (finite state automaton, FSA):
決定性有限オートマトン (deterministic finite automaton, DFA)
と非決定性有限オートマトン (non-deterministic finite
automaton, NFA)
- 正規文法 (regular grammar): 左線形文法 (left linear grammar) と
右線形文法 (right linear grammar)
これらは全て同じ力を持って、正規言語を定義・受理する
これらを表現する「正規表現」(regular expression)
という協力な表現方法が存在
正規表現の例
計算機実習 I の演習問題: ある文章中に
&, ", ',
<, > を見つけて、それぞれを
&, ", ', <,
> に変換せよ。
Ruby で書くと次のようになる:
gsub /"/, '"'
gsub /'/, "'"
gsub /</, '<'
gsub />/, '>'
gsub /&/, '&'
正規表現の原則
- 文字そのものと、連結、選択肢、繰り返しが表現したい
- 「普通」の文字を自分自身で表現
- 一部の文字に特定な役割を持たせる
(メタ文字、meta-characters)
正規表現の形式定義
アルファベットΣ 上の正規表現と表す言語
| 優先度 |
正規表現 |
条件 |
言語 |
備考 |
|
ε, a |
a ∈ Σ |
{ε} 又は {a} |
|
| 低い |
r|s |
r, s が正規表現 |
L(r|s) = L(r) ∪
L(s) |
集合和 |
| 低め |
rs |
r, s が正規表現 |
L(rs) =
L(r)L(s) |
連結 |
| 高め |
r* |
r が正規表現 |
L(r*) = (L(r))* |
閉含 |
| 高い |
(r) |
r が正規表現 |
L((r)) = L(r) |
|
L(r) は r によって定義される言語
正規表現の意義
- 正規表現が定義する言語は文法でも書ける
- 文法は複数の書き換え規則なので描きにくい、分かりにくい
- 正規表現は一つなので、書きやすい、直観的で分かりやすい
正規表現自体の文法
- 正規表現自体も一つの言語
(全ての正規表現の集合)
- 正規言語ではなく、文脈自由言語
- 文法: R → ε, R →a, R →b,..., R
→R|R, R →RR,
R →R*, R →(R)
優先度に要注意
- abc* と (abc)*
- a|b|c* と (a|b|c)*
- ab|c と a(b|c)
正規表現の例
- ある一個の語だけ受理できる:
word
- ある記号の数が奇数 (
(aa)*a)、偶数
((aa)*)、3で割れば余りが 2
(aa(aaa)*)、等
- 語の先頭に決まった記号列がある:
abc(a|b|c)*
- 語の終わりに決まった記号列がある:
(a|b|c)*abc
- 語の真ん中に・どこかに決まった記号列がある:
(a|b|c)*abc(a|b|c)*
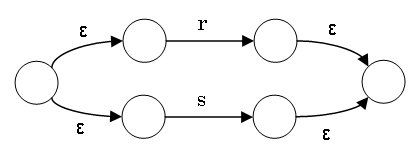
正規表現から NFA へ (文字、選択肢)
正規表現に対応する NFA
は正規表現の部分表現から再帰的に作成可能
ε と a に対応する NFA
は初期状態一つと受理状態一つとそれを結ぶ ε 又は a
と書かれた矢印
r|s の NFA は r の NFA と s の NFA から次のように作成:
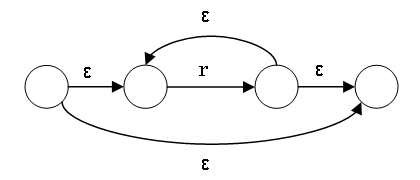
正規表現から NFA へ (連結、繰返し)
rs の NFA は r の受理状態と s の初期状態を ε で結んで、r
の初期状態は rs の初期状態、s の受理状態は
rsの受理状態。
r* の NFA は次のように作成:
有限オートマトンから正規表現へ
変換は可能が、複雑
変換の原理:
- 状態 A から状態 B
へ直接遷移できる正規表現を全ての状態の組み合わせのために作成
- 一個の状態だけを選んで、その状態の経由を含める正規表現を作成
- 2. のステップを繰り返して、経由できる状態を増加
- 途中で正規表現がどんどん複雑になるので、できる限り簡単化
正規表現の応用
- コンパクトで簡単に様々なパターンが表現可能
- 理論が実装に直結
- 多くのプログラム言語で組み込まれている (Ruby,
Javascript, Perl, Python,...)
- 他の言語でライブラリとして使用可能 (Java, C#, C,...)
- 多くのエディタでも使用可能
- 理論的な正規表現と実用化された正規表現は様々な面で異なる
実用化された正規表現: 記述上の違い
正規表現の便利な追加機能
(括弧内は相当する理論的な正規表現)
.: 文字一個 (a|b|c|...)- r
+: 一個以上の r
(rr*)
- r
?: r の有無 (r|ε,
その代わり ε は使わない)
- r
{m,n}:
m 個以上 n 個以下の r
(r...rr?...r?)
[acdfh]: 複数の文字から選択
((a|c|d|f|h))[b-f]: b から f の字 ((b|c|d|e|f))\* 等: \
はメタ文字のエスケープに使われる
実用化された正規表現: 使い方の違い
- 語全体のではなくその一部をマッチ
^ と $ などで語 (行)
の先頭と最後をマッチ- 結果はマッチの有無だけではなく、場所も含む
- マッチはできる限り選択肢の左側、できる限り長め
- 括弧に相当する部分語は変数に代入可能
- 変数の正規表現内の再利用
実用化された正規表現の応用
- 文書検索
- 文書の置き換え (一回または複数)
- 文書の区切り
実用化された正規表現の注意点
- 能力は DFA/NFA/正規言語を超える場合がある
- 実装がバックトラッキングを使用
- 一部の正規表現が一部の入力で非常に遅くなる
例: 文字列 an, 正規表現
a?nan (n=3:
文字列: aaa、正規表現: a?a?a?aaa, n~25
あたりから本格的に遅い)
今週のまとめ
- 正規表現、線形・正規文法、有限オートマトンは全部同じ表現能力・受理能力を保持
- DFA は効率良い受理の実装方法
- 正規表現はコンパクトな定義方法
- これらは字句解析に有効に使用可能
- しかし、これらに表現できない言語が存在
状態の有限な数によって、例えば一般の括弧の対応する言語は判定不可能
演習問題
(提出不要)
- 次の正規表現を NFA に変換し、NFA から DFA を作る:
(a|c*)a|b
- 1. の言語を定義する右線形文法を作る。
- Σ = {0, 1} の 0 が偶数 (1 は何個でもよい) 語を受理する
DFA を作る。
- (発展問題) 3. の言語の正規表現を作る。(ヒント:
変換するより正規表現を新たに作る方がいい)
次回の予定と準備
予定:
準備:
- 復習
- flex, bison, gcc, make の動作確認済みノート PC を持参